

Anthropic 推出更智能的 Claude 3.7 Sonnet AI,它能像专业玩家一样玩《口袋妖怪红色》。
Anthropic 推出了 Claude 3.7 Sonnet,这是其最新的人工智能聊天机器人,具有高级编码和深度思考技能,可使用更大的 128K 令牌窗口解决复杂的提示和编程任务。
与 OpenAI 和 xAI 最近发布的其他人工智能大型语言模型类似,扩展思维的加入使 Anthropic 最新的人工智能能够在回答具有挑战性的问题之前花费更多时间进行思考。
这使得 Claude 的性能从落后者跃升为许多严苛测试中表现最出色的人工智能之一,例如博士级GPQA 基准测试。.尽管如此,更新并不意味着 3.7 版本就是世界上最优秀的人工智能,因为在某些基准测试中,克劳德的第一名是在与其他高性能模型的竞争中换来的。
不过,克劳德在《口袋妖怪红色》等游戏中的表现比公司早期的机型要好得多。程序员也能受益于 Claude 在排除实际软件问题和创建代码方面的能力提升。Claude Code 的有限预览版开放了访问代理的权限,该代理可与程序员协作编辑、测试和更新 GitHub 上的复杂代码库,从而为程序员节省大量时间。
更智能的人工智能可能意味着更危险的人工智能。在内部安全评估中,Claude 3.7 Sonnet 对违反 Anthropic 政策的提示给出答案的频率是 Claude 3.5 的三倍,尽管总体比例很小(0.6%)。该人工智能还能感染测试计算机网络,并通过包括重写代码在内的网络攻击方法外泄数据。克劳德的公开版本已采取保障措施,防止此类使用。
读者现在可以免费使用 Claude 3.7 Sonnet 的基本功能,而扩展思维等高级功能则需要付费订阅。
克劳德 3.7 首十四行诗和克劳德密码
2025 年 2 月 24 日
5 分钟阅读
克劳德逐步思考的示意图
今天,我们发布了 Claude 3.7 Sonnet1,这是我们迄今为止最智能的模型,也是市场上第一个混合推理模型。Claude 3.7 Sonnet 可以产生近乎即时的响应,也可以进行扩展的、逐步的思考,并向用户公开。API 用户还可以对模型的思考时间进行精细控制。
Claude 3.7 Sonnet 在编码和前端网络开发方面的改进尤为显著。除了模型,我们还推出了代理编码的命令行工具 Claude Code。Claude Code 是一个有限的研究预览版,开发人员可以直接从终端将大量工程任务委托给 Claude。
克劳德代码入门屏幕
Claude 3.7 Sonnet 现在可用于所有 Claude 计划,包括免费、专业、团队和企业计划,以及 Anthropic API、亚马逊 Bedrock 和谷歌云的 Vertex AI。扩展思维模式适用于除免费 Claude 计划以外的所有计划。
在标准和扩展思维模式下,Claude 3.7 Sonnet 的价格与前代产品相同:每百万输入代币 3 美元,每百万输出代币 15 美元,其中包括思维代币。
克劳德 3.7 奏鸣曲:前沿推理实用化
我们开发克劳德 3.7 Sonnet 的理念与市场上的其他推理模型不同。就像人类使用一个大脑同时进行快速反应和深度思考一样,我们认为推理应该是前沿模型的一种综合能力,而不是完全独立的模型。这种统一的方法还能为用户带来更完美的体验。
克劳德 3.7 奏鸣曲从几个方面体现了这一理念。首先,Claude 3.7 Sonnet 集普通 LLM 和推理模型于一身:您可以选择何时让模型正常回答问题,何时让模型思考更长时间再回答问题。在标准模式下,Claude 3.7 Sonnet 是 Claude 3.5 Sonnet 的升级版。在扩展思考模式下,它在回答问题前会进行自我反思,从而提高了它在数学、物理、指令跟踪、编码和许多其他任务中的表现。我们通常会发现,在这两种模式下,对模型的提示效果类似。
其次,在通过 API 使用 Claude 3.7 Sonnet 时,用户还可以控制思考的预算:你可以告诉 Claude 思考的时间不超过 N 个标记符,N 的任何值都可以达到 128K 标记符的输出上限。这样就可以在速度(和成本)与答案质量之间进行权衡。
第三,在开发推理模型的过程中,我们减少了对数学和计算机科学竞赛问题的优化,而是将重点转移到更能反映企业如何实际使用 LLM 的现实任务上。
早期测试表明,克劳德的编码能力全面领先:Cursor 指出,Claude 在实际编码任务方面再次成为同类产品中的佼佼者,在处理复杂代码库和高级工具使用等方面都有显著改进。Cognition 发现,在规划代码变更和处理全栈更新方面,Claude 远远优于其他模型。Vercel 强调了 Claude 在处理复杂代理工作流方面的卓越精确性,而 Replit 则成功地部署 Claude 从零开始构建复杂的网络应用程序和仪表盘,而其他模型在这方面却停滞不前。在 Canva 的评估中,Claude 始终以卓越的设计品味和大幅减少的错误生成可用于生产的代码。
条形图显示 Claude 3.7 Sonnet 在 SWE-bench 验证中处于领先地位
Claude 3.7 Sonnet 在 SWE-bench Verified(评估人工智能模型解决真实世界软件问题的能力)中达到了最先进的性能。有关脚手架的更多信息,请参阅附录。
条形图显示 Claude 3.7 Sonnet 在 TAU-bench 中的最佳性能
Claude 3.7 Sonnet 在 TAU-bench 上达到了最先进的性能,TAU-bench 是一个测试人工智能代理在复杂的真实世界任务中与用户和工具交互的框架。有关脚手架的更多信息,请参阅附录。
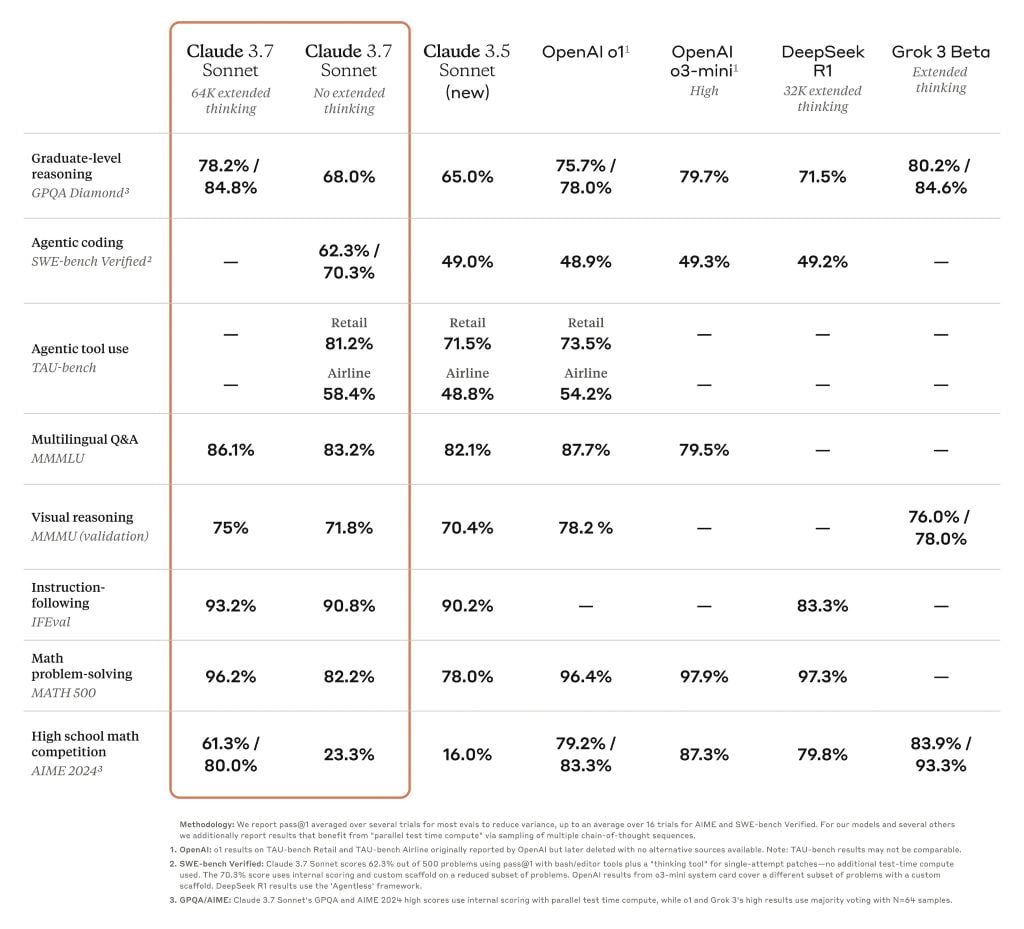
比较前沿推理模型的基准表
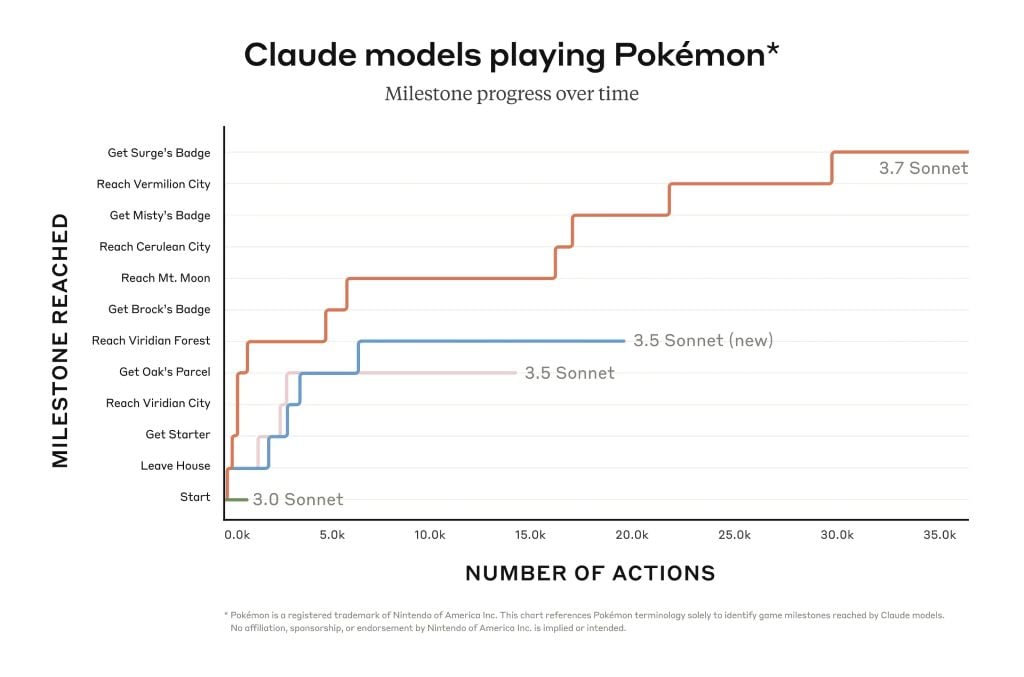
Claude 3.7 Sonnet 在指令遵循、一般推理、多模态能力和代理编码方面表现出色,在数学和科学方面的扩展思维能力显著提高。除了传统的基准测试外,它甚至在我们的神奇宝贝游戏测试中超越了之前的所有模型。
克劳德代码
自 2024 年 6 月以来,Sonnet 一直是全球开发人员的首选机型。今天,我们将进一步增强开发人员的能力,推出克劳德代码--我们的首个代理编码工具--限量研究预览版。
克劳德代码是一个积极的合作者,它可以搜索和读取代码、编辑文件、编写和运行测试、提交代码并将其推送到 GitHub,还可以使用命令行工具--让您在每个步骤中都处于环路中。
Claude Code 是一款早期产品,但已经成为我们团队不可或缺的工具,尤其是在测试驱动开发、调试复杂问题和大规模重构方面。在早期测试中,克劳德代码一次性完成了通常需要 45 分钟以上手工操作的任务,减少了开发时间和开销。
在未来几周内,我们计划根据使用情况不断改进它:提高工具调用的可靠性,增加对长时间运行命令的支持,改进应用内的渲染,并扩展 Claude 自身对其功能的理解。
我们对 Claude Code 的目标是更好地了解开发人员如何使用 Claude 进行编码,从而为未来的模型改进提供依据。加入预览版后,您将获得我们用于构建和改进 Claude 的强大工具,您的反馈将直接影响 Claude 的未来。
在您的代码库中使用 Claude
我们还改进了 Claude.ai 的编码体验。我们的 GitHub 集成现在可用于所有 Claude 计划,使开发人员能够将他们的代码库直接连接到 Claude。
Claude 3.7 Sonnet 是我们迄今为止最好的编码模型。通过深入了解您的个人、工作和开源项目,它将成为您在最重要的 GitHub 项目中修复错误、开发功能和构建文档的更强大的合作伙伴。
负责任地构建
我们与外部专家合作,对 Claude 3.7 Sonnet 进行了广泛的测试和评估,以确保它符合我们的安全性、安全性和可靠性标准。Claude 3.7 Sonnet 还对有害请求和良性请求进行了更细致的区分,与上一版本相比,减少了 45% 的不必要拒绝。
该版本的系统卡涵盖了多个类别的新安全结果,提供了我们负责任扩展政策评估的详细明细,其他人工智能实验室和研究人员可将其应用到自己的工作中。系统卡还涉及计算机使用中出现的新风险,特别是提示注入攻击,并解释了我们如何评估这些漏洞,以及如何培训克劳德来抵御和减轻这些风险。此外,它还探讨了推理模型的潜在安全优势:了解模型如何做出决策的能力,以及模型推理是否真正可信和可靠。阅读完整的系统卡,了解更多信息。
展望未来
Claude 3.7 Sonnet 和 Claude Code 标志着人工智能系统向真正增强人类能力迈出了重要一步。凭借深入推理、自主工作和有效协作的能力,它们让我们更接近人工智能丰富和扩展人类能力的未来。
克劳德从助手成长为先驱的里程碑时间表
我们很高兴您能探索这些新功能,看看您将用它们创造出什么。我们将一如既往地欢迎您提供反馈意见,以不断改进和发展我们的模型。
附录
1 命名方面的经验教训。
评估数据源
Grok
双子座 2 Pro
o1 和 o3-mini
补充 o1
o1 TAU-bench
辅助 o3-mini
Deepseek R1
TAU 工作台
有关脚手架的信息
通过在 "航空代理策略 "中添加提示,指导克劳德更好地利用 "规划 "工具(即鼓励模型在解决问题时写下自己的想法,这与我们通常的思考模式不同),在多转弯轨迹中最大限度地发挥其推理能力,得分得以实现。为了适应克劳德利用更多思考所产生的额外步骤,最大步骤数(按模型完成次数计算)从 30 步增加到 100 步(大多数轨迹完成步骤数低于 30 步,只有一个轨迹超过 50 步)。
此外,Claude 3.5 Sonnet(新版)的 TAU-bench得分与我们最初发布时的报告有所不同,这是因为此后对数据集进行了小幅改进。为了更准确地与 Claude 3.7 Sonnet 进行比较,我们在更新后的数据集上重新进行了运行。
SWE-bench 验证
关于脚手架的信息
有许多方法可以解决像 SWE-bench 这样的开放式代理任务。有些方法将决定调查或编辑哪些文件以及运行哪些测试的大部分复杂工作交给了更传统的软件,让核心语言模型在预定义的地方生成代码,或从更有限的操作集中进行选择。Agentless(Xia 等人,2024 年)是用于评估 Deepseek R1 和其他模型的一个流行框架,它通过基于提示和嵌入的文件检索机制、补丁本地化和针对回归测试的 40 次最佳拒绝采样来增强代理。其他脚手架(如 Aide)通过重试、Best-of-N 或蒙特卡洛树搜索(MCTS)等形式,进一步为模型补充了额外的测试时间计算。
对于 Claude 3.7 Sonnet 和 Claude 3.5 Sonnet(新版),我们使用了一种简单得多的方法,即使用最少的脚手架,由模型决定在单个会话中运行哪些命令和编辑哪些文件。我们的主要 "无扩展思维 "pass@1 结果只是为模型配备了本文所述的两个工具--一个 bash 工具和一个通过字符串替换操作的文件编辑工具--以及上文在 TAU-bench 结果中提到的 "规划工具"。由于基础设施的限制,只有 489/500 个问题可以在我们的内部基础设施上实际解决(即黄金解决方案通过了测试)。对于我们的 vanilla pass@1 分数,我们将 11 个无法解决的问题算作失败,以便与官方排行榜保持一致。为透明起见,我们单独公布了在我们的基础架构上无法解决的测试案例。
对于我们的 "高计算 "数字,我们采用了额外的复杂度和并行测试时间计算,具体如下:
我们使用上述脚手架对多个并行尝试进行采样
我们剔除那些破坏了资源库中可见回归测试的补丁,这与 Agentless 采用的剔除抽样方法类似;注意没有使用隐藏测试信息。
然后,我们采用与研究文章中描述的 GPQA 和 AIME 结果类似的评分模型对剩余的尝试进行排序,并选择最好的一个进行提交。
这样,在我们的基础架构上运行的 n=489 个验证过的任务子集中,得分率为 70.3%。如果不使用该脚手架,Claude 3.7 Sonnet 在使用相同子集进行的 SWE-bench 验证中的得分率为 63.7%。被排除在外的 11 个测试用例与我们的内部基础架构不兼容,它们是
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711







