

CheckMag | 如何使用 Invoke AI 和 Stable Diffusion 托管自己的人工智能图像生成器
您有很多理由想要托管自己的 AI 图像生成器。无论你是想避开水印和广告,还是想在无需订阅的情况下生成多张图片,抑或是想在道德允许的范围之外生成图片,托管你自己的实例并使用像 Stable Diffusion 这样的公司提供的训练数据,都能让你保留最终的控制权。服务,托管自己的实例并使用像 Stable Diffusion 这样的公司提供的训练数据,都可以让您对人工智能生成的图像保留最终控制权。
要开始使用,您需要从下载 Invoke AI 社区版。.在 Windows 下,几乎所有的安装过程都是自动完成的,所有需要的依赖项都已安装。不过,Linux 和 macOS 版本可能并非如此,因此具体情况可能会有所不同。在实验中,我们使用了一台运行 Windows 11 的虚拟机,它配备了 Ryzen 9 5950 分配的 8 个核心、一个 RTX 4070(亚马逊有售)通过虚拟机运行,24GB 内存在 1TB NVMe 固态硬盘上运行。支持 AMD GPU,但仅限于 Linux 系统。
完成安装过程后,启动 Invoke AI 生成配置文件,然后关闭。这样做的原因是,建议对系统的各个部分进行一些更改,以激活 "低内存模式"。
虽然 Invoke AI 并未明确指出什么是低 VRAM,但 RTX 4070 的 12GB 内存可能无法运行 24GB 的模型。要做到这一点,你必须用文本编辑器编辑安装文件夹中的 invokeai.yaml 文件,并添加以下一行:
enable_partial_loading: true
编辑完成后,运行 Nvidia GPU 的 Windows 用户需要在 Nvidia 控制面板的全局设置中将 CUDA - Sysmem Fallback Policy(系统内存回退策略)设置为 "Prefer No Sysmem Fallback"(首选无系统内存回退)。您可以自定义分配给 VRAM 的缓存量,但对于大多数人来说,只需打开 "低 VRAM 模式 "即可开始使用。
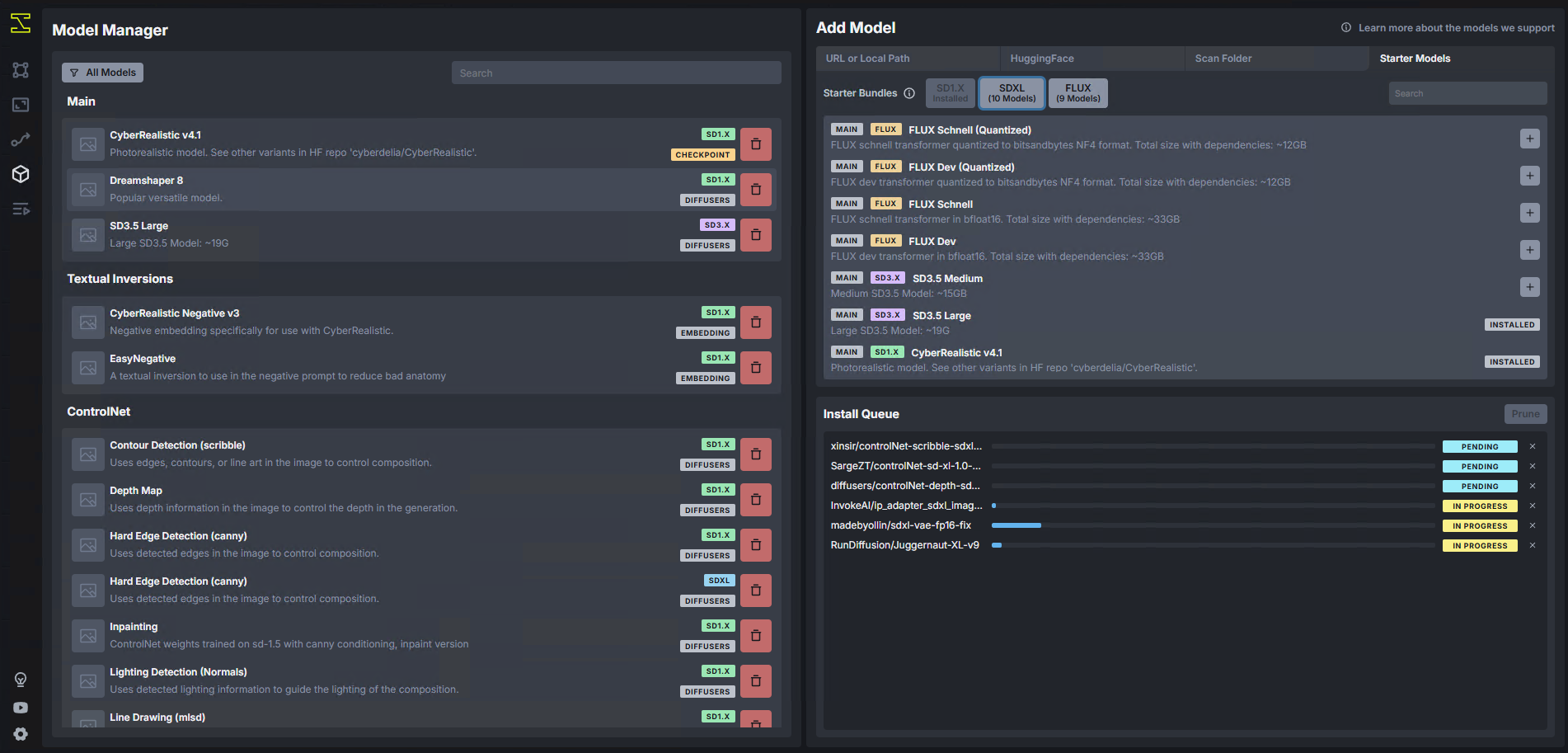
有些模型可以立即下载,如Dreamshaper 和CyberRealistic,但要使用稳定扩散,您需要创建Hugging Face账户,并生成一个令牌以允许 Invoke AI 下载模型。不过,也有通过 URL、本地路径或扫描文件夹添加模型的方法。要创建令牌,请单击右上角的账户头像并选择 "访问令牌"。您可以随意调用令牌,但需要提供以下访问权限:

复制令牌并将其粘贴到 "模型 "选项卡 "拥抱的脸"部分的框中。您可能需要在网站上确认后才能允许访问。您不必注册更新,Invoke AI 会在您需要授予访问权限时提示您。
请记住,根据您选择下载的内容,各种模型都会占用相当大的存储空间。稳定版 Diffusion 3.9 大约需要 19 GB。
如果一切设置正确,就可以开始工作了。您可以通过主机上的网络浏览器访问界面,方法是访问http://127.0.0.1:9090.本地网络上的其他机器也可以访问该界面。
在 "画布 "选项卡上,您可以输入文本提示来生成图像。在 "画布 "选项卡上,您可以输入一个文本提示来生成图像,在文本提示下方,您可以设置要生成图像的分辨率;请注意,分辨率越高,生成过程所需的时间就越长,不过您也可以先生成较低分辨率的图像,然后使用其中一个缩放工具来生成较高分辨率的图像。下面,您可以选择要使用的模型。在测试的 4 个模型(Juggernaut XL、Dreamshaper 8、CyberRealistic v4.8 和 Stable Diffusion 3.5(大))中,Stable Diffusion 生成的图像更逼真,但在解释文本提示时有问题,而其他模型生成的图像则类似于游戏中的剪切场景。

显然,最好的模型就是能为您的使用案例提供最佳效果的模型。到目前为止,"稳定扩散 "的速度是最慢的,大约需要 30 到 50 秒才能生成一幅图像,但在所有测试的 4 个模型中,其结果无疑是最逼真、最令人愉悦的。
提示:
- 左上角一位聪明的女士走在街道上,回头看着镜头,左侧是车流
- 右上图一只哈巴狗在舔香蕉
- 左下角坐在月球表面半个蛋壳里的玩具太空人
- 右下图金发碧眼的女孩在家吃爆米花

Invoke AI 还有很多值得探索的地方。通过该工具,您可以重新制作图像的各个部分、进行迭代、完善图像并创建工作流程。运行它并不需要过多的硬件,Windows 版本可以在任何 10xx 系列或更高版本的 Nvidia GPU 上运行,不过在生成图像时可能会稍慢一些。虽然对人工智能模型的训练和所需的能耗褒贬不一,但在自己的硬件上本地运行人工智能是为各种用途生成免版税图像的好方法。







